整篇文章基本上是描述对于twitter上的spammer进行检测。
本文中作者不关心twitter中的广告用户,只对含有恶意URL链接的用户感兴趣。
首先是用了2个方法来检测恶意或者是钓鱼的URL。
①Google Safe Browsing (GSB) 该方法是基于黑名单
②URL honeypot 基于Capture-HPC 在虚拟机中使用真实浏览器浏览URL
接着对恶意用户的规避策略进行了分析。
大致上可以分为两类:
①profile-based feature 根据关注数、粉丝数、发推数(followings、followers、tweets)
②content-based feature 根据发推内容包含的URL链接所占比例 恶意账号可以通过获取更多的粉丝(gainning more followers:购买、交换、自我创造)和发送更多推文(使用工具:Auto Twitter 、Twitter API)两种方法来规避基于轮廓的特征策略。
通过混要正常推文发送(Mixing Normal Tweets)和发送混杂推文(Posting Heterogeneous Tweets:不同的描述方式来重复同一内容:Spinbot)这两种方法来规避基于内容的特征策略。
作者设计了10个检测特征,包含:3个基于图的特征(graph-based features)、3个基于邻接点的特征(Neighbor-based features)、3个基于自动化的特征(automation-based features)和1个基于时间的特征(timing-based feature)。
基于图的特征和基于邻接点的特征是为了检测那些企图通过控制自己的社交行为来绕过基于轮廓特征检测策略的恶意账号,这些账号可以在一定程度上管理自己的行为,但是难以改变他们的关注用户和粉丝的行为。
基于自动化的特征和基于时间的特征是为了检测那些通过增加合理合法推文来规避内容检测的用户。
A.Graph-based feature
即使spammer能改变其自身的一些行为,但是想改变其在图中所处的位置还是比较难的。
将 twitter account 视为 结点→ i
每个关注关系视为有向边 → e
得到有向图(directed graph) G=(V,E)
设置了三个特征值
①local clustering coefficient 本地集聚系数
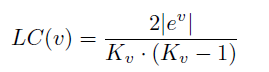
| ev | 表示所有邻接节点之间的所有的边数 |
Kv表示该节点入度出度的和
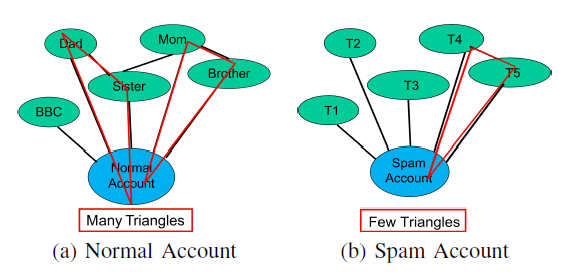
可见spammer的本地集聚系数会比较小。
②betweenness centrality 中介中心性(中间中心度)
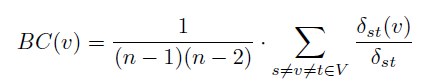
δst(v)表示从s到t所有包含v结点的最短路径数
δst表示从s到t所有的最短路径数
n表示所有结点数
中间成员对路径两端的成员具有更大的“人际关系影响”。如果一个成员位于其他成员的多条最短路径上,那么该成员就是核心成员,就具有较大的中间核心性。 量化:
(1)各条线路的权系数相等;
(2)通讯过程中总是走最短路径;
(3)当存在不止一条最短路径时,每一条的使用概率相等。
本质:网络中包含成员 i 的所有最短路径的条数占所有最短路径条数的百分比。表示成员 i 的控制能力。(更多内容可以参考维基百科)
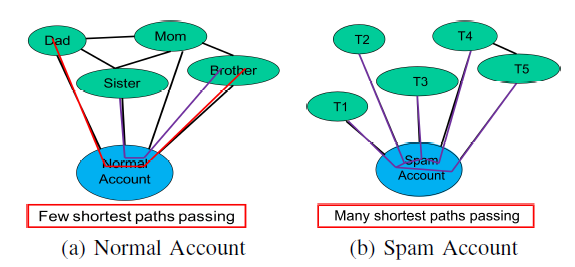
可见spammer会有更高的中介中心性。
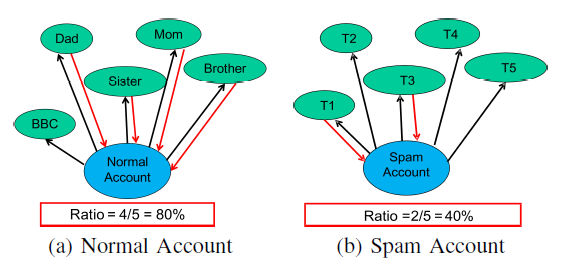
③bi-directional links ratio 双向链接比
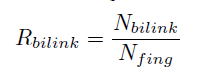
Nbilink表示双向链接数
Nfing表示关注的人数
B.Neighbor-based feature
①average neighbors’ followers
②average neighbors’ tweets
③following to median neighbors’ followers 前两个特征主要是关注用户的粉丝数量平均值与发推数量平均值。
C.Automation-based feature
①API2 Ratio 通过API发推数/总发推数
②API URL Ratio 包含URL的通过API发送的推数/通过API发推总数
③API Tweet Similarity API发推的相似度
D.Timing-based feature following rate 关注其他用户的速度
(未完待续)